Homo Economicus versus Homo Sapiens
Dick Thaler and Cass Sustein in their NY TIMES bestseller, NUDGE, describe two people in the world:
- Econs and Humans, also known as Homo Economicus and Homo Sapiens.
I want to make the case that all *humans* should utilize systematic decision-making processes.
My plea is not a story; my defense for systematic model driven investment is based on the empirical evidence.
Cold. Hard. Scientific evidence.
The empirical evidence on the subject of model-driven decision making versus expert-driven, or “gut-instinct” decision making, has been described by the late Paul Meehl, one of the greatest minds in psychology, as the only controversy in social science with “such a large body of qualitatively diverse studies coming out so uniformly in the same direction.”
In as many words, models beat experts.
How can simple models possibly beat experts?
Dan Kahneman’s tour de force, “Thinking, Fast and Slow,” makes a painful observation: Human behavior is flawed.
The example below highlights just how wrong we can be.
Source: http://web.mit.edu/persci/people/adelson/checkershadow_illusion.html

Stare at cells A and B. Do they look different?
If you are a human, they will be different.
If you are an econ, or a computer, you will compare RGB values and identify that each is 120-120-120.
A and B are the same.
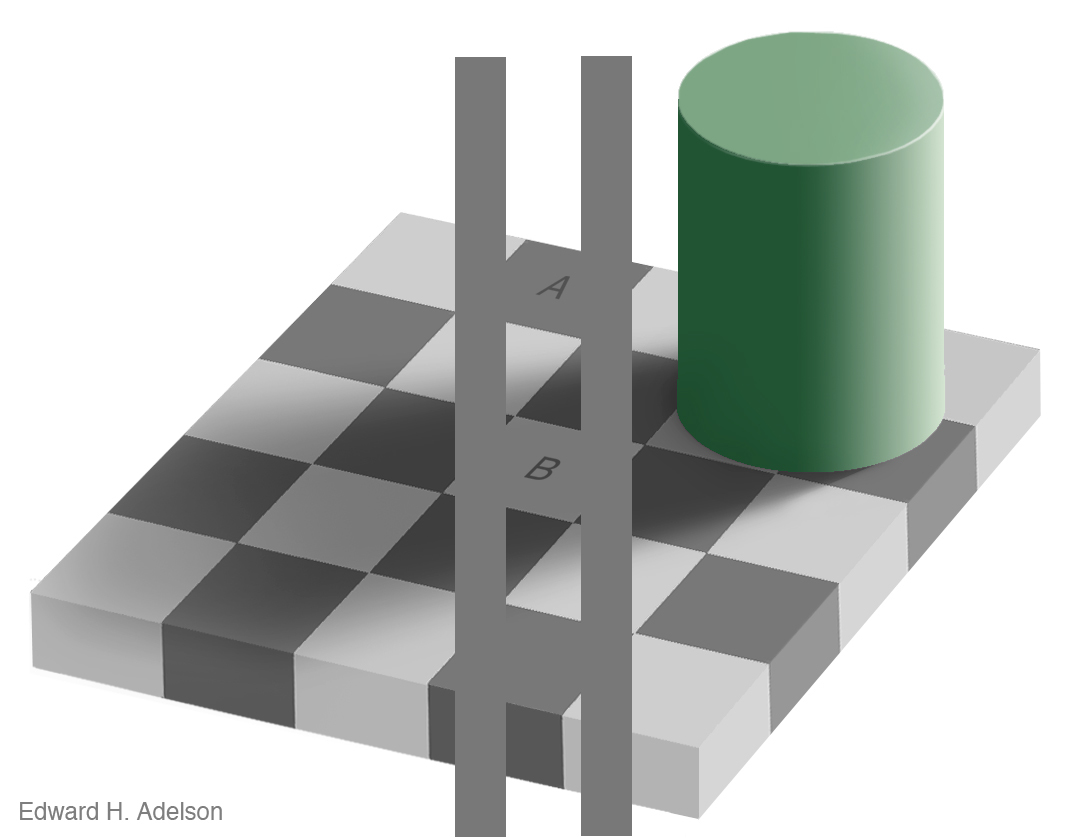
Impossible you say? Maybe.
Nonetheless, the lesson here is clear: Perception is not reality.
A study on the subject of models vs. experts
The study we’ll examine is called “Clinical Detection of Intellectual Deterioration Associated with Brain Damage.”
Here is the abstract:
The article makes a preliminary assessment of the clinical utility of the classification information provided by the discriminant function weights through a clinical-actuarial classification paradigm. Researchers quantified the relationships of educational level and occupation with the Wechsler-Bellevue Full Scale IQ as two signs of intellectual deterioration. Wechsler-Bellevue Intelligence Scale Form I (W-B) protocols were obtained from brain-impaired individuals and nonpsychotic non-brain-impaired individuals who were administered the W-B alone or as part of the Halstead-Reitan Neuropsychological Test Battery. The number of significant correlations between classification accuracy and decision confidence indicates that several of the interns tended to be more confident when they were classifying a protocol as nonimpaired in both judgment conditions.
Translation: Pit man vs. machine in a horse race to see who can better classify the extent of brain impairment based on test of intelligence and environmental factors.
- The model utilizes a systematic approach based on a statistical model of prior data.
- The humans utilize their experience and intuition.
- In some samples the humans receive the model, in other case they do not.
Here is a summary of the key results:
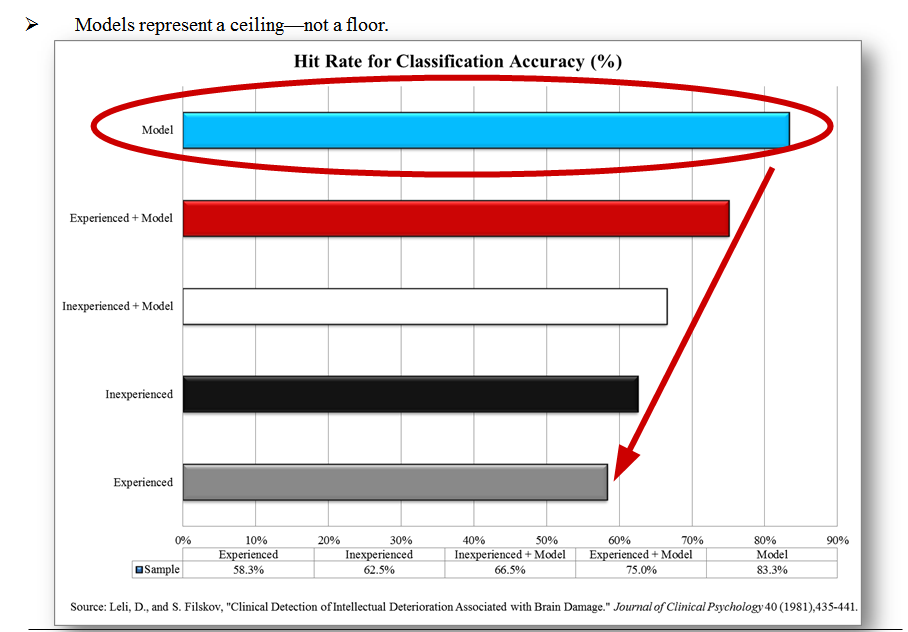
The model represents a ceiling for performance.
Humans with a model improve performance, but underperform the model.
Humans without a model are ineffective.
But what about in investing?
Investors are much more sophisticated than psychologists and doctors. They have access to much better tools and information. Expert investors can’t possibly be beaten by simple models, can they?
Quantamental, or part quantitative, part fundamental, is a concept often sold (not bought) by investors. These “quantamental” salesmen are clearly naive to the evidence that models represent a ceiling on performance–not a floor.
Case in point: Greenblatt performs a controlled study on this concept in the context of his magic formula.
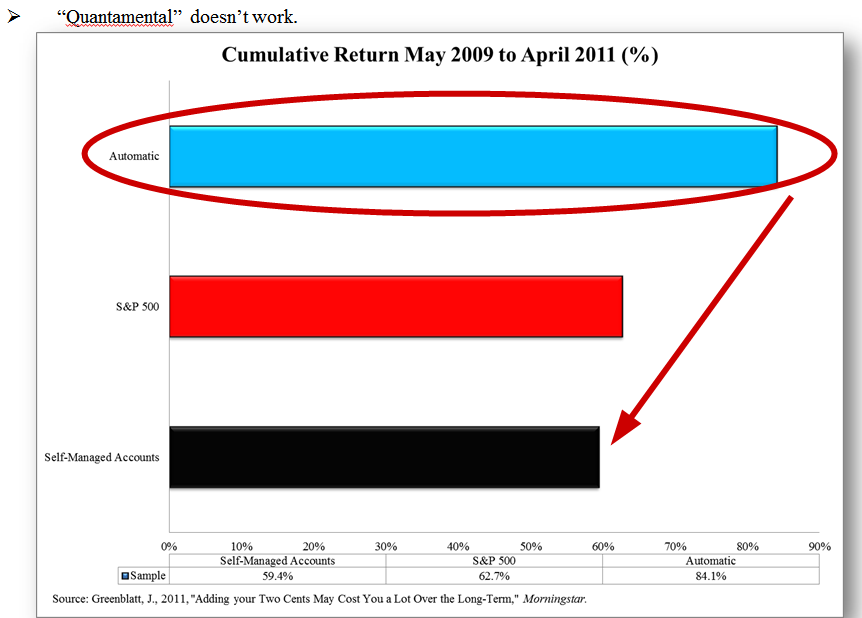
Following the model performs the best.
The S&P does pretty well.
Following the model, but then trying to add value via intuition, actually destroys the model”s benefit and causes these investors to underperform the market. This evidence is a replica of the evidence from the brain impairment study.
But how widespread is this phenomenon?
Sure, there is a one-off study by Greenblatt, and some geeky brain damage study performed by psychologists that was published 30 years ago.
All the other studies show clear evidence that experts beat models, right?
Wrong.
Grove et al. conduct a meta-analysis–a study of studies–on 136 studies published articles that analyze the accuracy of “actuarial” (i.e., computers/models) vs. “clinical” (i.e., human experts) judgement.
The studies cover everything–literally (click to enlarge)
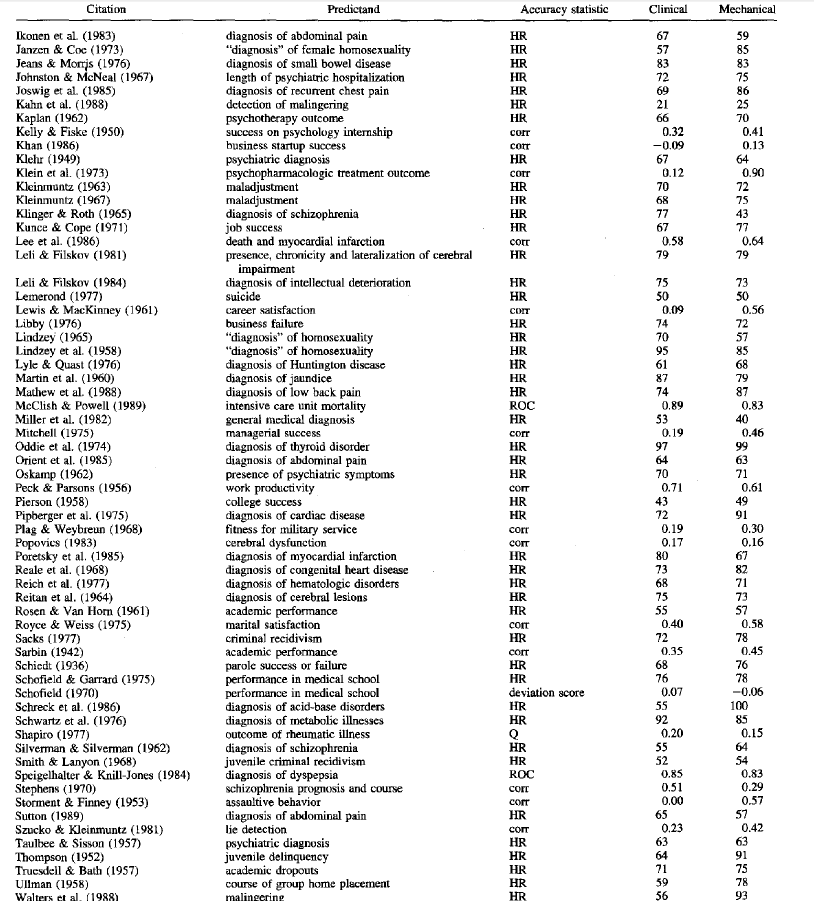

The chart below summarizes the results:
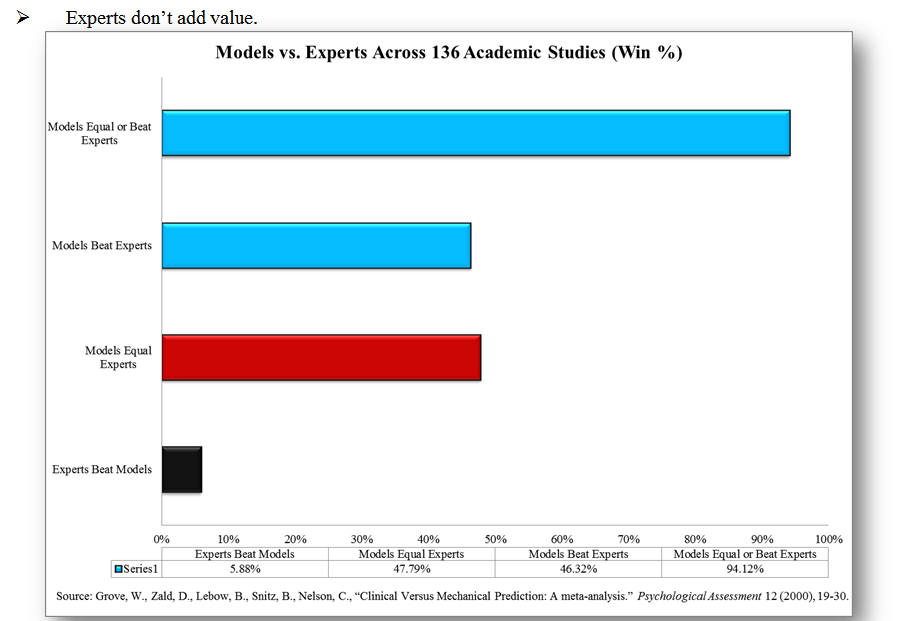
Models equal or beat experts 94% of the time.
Experts beat models 6% of the time.
The empirical evidence is overwhelming and clear: Models beat experts.
Seriously, how can this be possible?
Psychologists have studied the highly counter-intuitive finding that models beat experts.
I’ve taken my best shot at narrowing it all down to 5 core reasons:
- Humans can take the same facts, but come to different decisions, depending on the stimuli in the environment, and their physiological status–if we wake up on the wrong side of the bed, we might come to a different conclusion than if we woke up feeling all bright and chipper.
- Computers don’t have this problem. Inputs in; analysis out.
- Human experts rely on rules of thumb; some work, but many are story-based and not empirical-based.
- For example, there is conflicting empirical evidence to suggest that buying high-quality firms (e.g., sorting firms on EBIT/capital) is a market-beating trading strategy, however, many investors focus a large amount of their investment focus on identifying high-quality firms and disregard much more important factors such as price. (A recent paper might suggest that quality can work)
- Humans get overconfident and overoptimistic. They typically develop an idea and come to a conclusion. Humans collect more and more information and get more and more confident in their conclusion, however, the accuracy of their conclusion never improves. A summary of a study highlighting this empirical observation can be found here:
- Computers don’t suffer from this problem. They don’t get emotionally involved and don’t have an ego. Therefore, they are unable to get overconfident or overoptimistic.
- The number of incorrect modifications experts impose on a model outnumber the number of correct modifications.
- Humans can create modifications to a model that can create value. A famous concept in psychology is the “broken leg theory.” Say a computer develops a model to predict when people will go to the movie theater. The human expert identifies that someone has a broken leg and is able to update the quantitative model and outperform the model. The issue is that the human is unable to limit their “tinkering” of the model to just one change. And all the evidence from academic research suggests that the number of incorrect modifications experts impose on a model outnumber the number of correct modifications. In summary, humans destroy the benefits of systematic models the minute they try and “improve’ them.
- Finally, we need to feel like our efforts are worthwhile.
- We need to fulfill what Maslow— famous for developing the human hierarchy of needs–calls our innate need for Esteem and self-actualization. Bowing down to the fact that simple models outperform experts directly challenges our ability to achieve goals, gain confidence, and feel a sense of achievement.
Some comments from the “experts” on the models vs. experts debate (ironic, I know):
The process of making judgments and decisions requires a method for combining data. To compare the accuracy of clinical and mechanical (formal, statistical) data-combination techniques, we performed a meta-analysis on studies of human health and behavior. On average, mechanical-prediction techniques were about 10% more accurate than clinical predictions. Depending on the specific analysis, mechanical prediction substantially outperformed clinical prediction in 33%-47% of studies examined. Although clinical predictions were often as accurate as mechanical predictions, in only a few studies (6%-16%) were they substantially more accurate. Superiority for mechanical-prediction techniques was consistent, regardless of the judgment task, type of judges, judges’ amounts of experience, or the types of data being combined. Clinical predictions performed relatively less well when predictors included clinical interview data. These data indicate that mechanical predictions of human behaviors are equal or superior to clinical prediction methods for a wide range of circumstances.
–Grove, Zald, Lebow, Snitz, and Nelson, “Clinical Versus Mechanical Prediction: A Meta-Analysis.
Another quote:
There is no controversy in social science that shows such a large body of qualitatively diverse studies coming out so uniformly in the same direction of this one [clinical vs. actuarial performance].
–Meehl, P.E, “Causes and effects of my disturbing little book.”
But EXPERTS ARE NOT WORTHLESS!!!
Experts are extremely value in our society.
In fact, experts are critical.
Experts are in charge of developing the algorithms and models we need to use in our lives to ensure we make accurate and reliable decisions that are unaffected by System 1 thinking.
However, the research I have outlined in this article highlight a crucial empirical observation:
Experts need to design the models, but COMPUTERS NEED TO IMPLEMENT THE MODEL.
Disclosures:
Performance figures contained herein are hypothetical, unaudited and prepared by Alpha Architect, LLC; hypothetical results are intended for illustrative purposes only.
Past performance is not indicative of future results, which may vary.
There is a risk of substantial loss associated with trading commodities, futures, options and other financial instruments. Before trading, investors should carefully consider their financial position and risk tolerance to determine if the proposed trading style is appropriate. Investors should realize that when trading futures, commodities and/or granting/writing options one could lose the full balance of their account. It is also possible to lose more than the initial deposit when trading futures and/or granting/writing options. All funds committed to such a trading strategy should be purely risk capital.
Hypothetical performance results (e.g., quantitative backtests) have many inherent limitations, some of which, but not all, are described herein. No representation is being made that any fund or account will or is likely to achieve profits or losses similar to those shown herein. In fact, there are frequently sharp differences between hypothetical performance results and the actual results subsequently realized by any particular trading program. One of the limitations of hypothetical performance results is that they are generally prepared with the benefit of hindsight. In addition, hypothetical trading does not involve financial risk, and no hypothetical trading record can completely account for the impact of financial risk in actual trading. For example, the ability to withstand losses or adhere to a particular trading program in spite of trading losses are material points which can adversely affect actual trading results. The hypothetical performance results contained herein represent the application of the quantitative models as currently in effect on the date first written above and there can be no assurance that the models will remain the same in the future or that an application of the current models in the future will produce similar results because the relevant market and economic conditions that prevailed during the hypothetical performance period will not necessarily recur. There are numerous other factors related to the markets in general or to the implementation of any specific trading program which cannot be fully accounted for in the preparation of hypothetical performance results, all of which can adversely affect actual trading results. Hypothetical performance results are presented for illustrative purposes only.
Indexes are unmanaged, do not reflect management or trading fees, and one cannot invest directly in an index.
There is no guarantee, express or implied, that long-term return and/or volatility targets will be achieved. Realized returns and/or volatility may come in higher or lower than expected.
About the Author: Wesley Gray, PhD
—
Important Disclosures
For informational and educational purposes only and should not be construed as specific investment, accounting, legal, or tax advice. Certain information is deemed to be reliable, but its accuracy and completeness cannot be guaranteed. Third party information may become outdated or otherwise superseded without notice. Neither the Securities and Exchange Commission (SEC) nor any other federal or state agency has approved, determined the accuracy, or confirmed the adequacy of this article.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of Alpha Architect, its affiliates or its employees. Our full disclosures are available here. Definitions of common statistics used in our analysis are available here (towards the bottom).
Join thousands of other readers and subscribe to our blog.