Johnny Paycheck has a great country song centered around the following lyric:
Take this job and shove it…I ain’t working here no more…
Campbell Harvey, in the 2017 AFA Presidential Address, elaborates an analogous comment on the current state of the financial economics field:
Take this alpha and shove it…I ain’t publishing this research no more…
Prof. Harvey is rightly concerned that the incentives to publish “strong significant results” are super high in finance and economics and this is skewing our true understanding of reality. In short, Campbell has the intellectual fortitude to state plainly what many of us have known — or indirectly sensed — data-mining is probably rampant in financial economics.

Here is a video lecture based on the topic — highly recommend everyone watch this for further understanding.
To be clear, Prof. Harvey is not saying that all research is bogus, he is just saying that we need to be much more skeptical, have much higher standards, and develop more sensible techniques, when determining if a specific research finding is robust and reliable. For example, here are past posts we’ve done on the topic:
- Overfitting bias
- Digging into the “factor zoo”
- A need to focus on sustainable active investing and identify the “pain,” to understand the potential gain.
Prof. Harvey also points out the following regarding our discussion on their “factor zoo” paper, which looks at over 300 published findings and identifies that the majority of these findings are false, because the t-stats need to be adjusted above 3:
…raise the threshold for discovering a new finding to t>3…
In this new discussion from Harvey, he makes an even more compelling point:
I would like to make the case today that making a decision based on t>3 is not sufficient either.
Prof. Harvey’s discussion emphasizes the importance of the 5 elements of “factor identification” discussed in Swedroe/Berkin’s new book on factor investing:
- Be persistent over a long period of time, and across several market cycles;
- Be pervasive across a wide variety of investment universes, geographies, and sometimes asset classes;
- Be robust to various specifications;
- Have intuitive explanations grounded in strong risk and/or behavioural arguments, with reasonable barriers to arbitrage; and,
- Be implementable after accounting for market impacts and transaction costs.
Why Should We Be Weary of “Evidence-Based Investing”
Some of the most interesting research I’ve done has never been published, probably because the work wasn’t that good, but also because the results showed a “non-result.” For example, one of my favorite research projects involved the investigation of the so-called “limited attention” hypothesis. Limited attention is a core concept behind our tweak on momentum investing (see “frog in the pan” concept). We collected a new dataset of all NYSE bell events, which served as an “attention shock,” and allowed us to do a relatively clean test on “limited attention” and question our core assumption that this bias influences asset prices.
Here is a short-hand version of what we found:
…limited attention has little influence on asset prices.
Here is a direct comment from the referee report we received from the journal:
Regardless of the economic story, I think the weak/no result in price movement makes the paper a tough sell and hurts its potential contribution.
Not sure one can find clearer evidence that there is a desire to publish “positive” results. Kinda sad, but also reality.
Here are some figures from Prof. Harvey’s paper, which highlight that our experience is not an anecdote, but potentially a normal operating procedure.
First, the figure below shows the distribution of t-stats associated with research published on so-called “factor studies.” (See here for a discussion on factor investing):
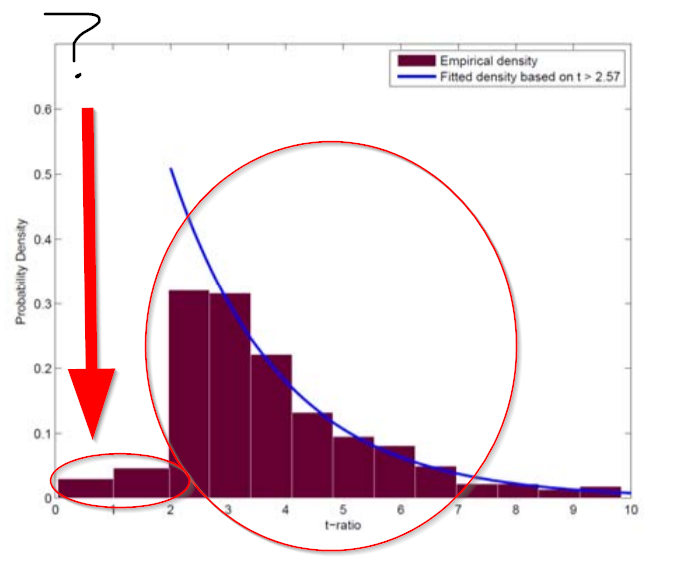
No t-stats? No publish.
Note that there are very few papers published, which show that something doesn’t work, but a ton of papers published showing that something does work. But one would think that knowing what doesn’t work is as important as knowing what does work — not according to the journal editors.
Next, we look at the broader academic research fields to see if this is “standard,” or unique to finance/economics. To address this question, Prof. Harvey looks to research from Fanelli (2010). Fanelli examines how likely various research fields will publish research that have “positive” findings related to a particular hypothesis:

Economists, and social sciences in general, are pretty bad. Psychology wins the grand prize for “data-mining.”
What Can the Academic Literature Do?
As Prof. Harvey points out, the American Statistical Association is aware of the problem that many researchers do not really understand statistical significance and that “the p-value has become a gatekeeper for whether work is publishable.” In reaction to the problem, the ASA released the following 6 principles to address the misuse of p-values:
- P-values can indicate how incompatible the data are with a specified statistical model.
- P-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone.
- Scientific conclusions and business or policy decisions should not be based only on whether a p-value passes a specific threshold.
- Proper inference requires full reporting and transparency.
- A p-value, or statistical significance, does not measure the size of an effect or the importance of a result.
- By itself, a p-value does not provide a good measure of evidence regarding a model or hypothesis.
Prof. Harvey suggests his own solutions to the problem:
- Better research methods
- Fix the agency problem.
Better Research Methods:
With respect to “better research methods,” the good professor’s recommendations revolve around transparency, better theory, and the use of a “Bayesion p=value,” which addresses the core question we really want answered: What’s the probability the null hypothesis is true, given the data? Of course, to calculate the Bayesian p-value, one has to input their prior thoughts on how likely the null hypothesis is true. For example, is there a 50% chance the size effect is real? Or is there a 2o% chance? Maybe if we are testing if “beta matters” we put the probability at 50%. But maybe if we are looking at the size effect we think the odds are 4/1, or there is only a 20% chance the null is false? The table below highlights how the Bayesian p-value can correct for our prior assumptions about how likely something is “real.”
How’s this work? Below, Prof. Harvey looks at the size effect and shows that the p-value is .0099, which essentially says that, given the null hypothesis is 0, the chance of seeing the observation is less than 1%. Pretty unlikely. But what if we think that the size effect, which we argue doesn’t have great economic theory behind it, is probably only “real” with a 20% chance? The Bayesian p-value is now .125, and basically says that the chance the null hypothesis is true (and our assumption it is correct with an 80% chance), given the data observed, is about 12.5% — which is a lot less compelling that <1%!
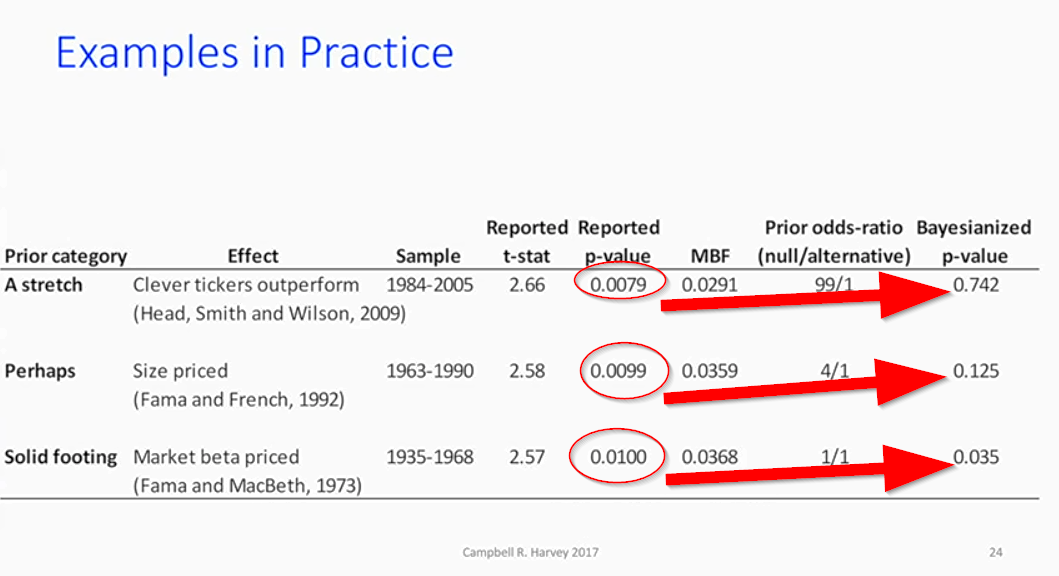
Anyway, the Bayesian p-value concept is pretty cool and allows one to ascertain up-front how likely the alternative hypothesis is true. If one thinks the alternative is totally ridiculous (e.g., stock tickers predict performance), the Bayesian p-value can account for this, whereas the standard p-value approach won’t cut it. Cool.
Fix the Agency Problem? Good Luck!
The agency problem, or the incentive for researchers to submit papers with strong statistical significance, is tough to tackle and Prof. Harvey suggests that solving this problem will be difficult.
Tough one to tackle.
The Scientific Outlook in Financial Economics
- Campbell Harvey
- A version of the paper can be found here.
Abstract:
It is time that we reassess how we approach our empirical research in financial economics. Given the competition for top journal space, there is an incentive to produce “significant” results. With the combination of: unreported tests, lack of adjustment for multiple tests, direct and indirect p-hacking, many of the research results that we are publishing will fail to hold up in the future. In addition, there are some fundamental issues with the interpretation of statistical significance. Increasing thresholds, such as t > 3, may be necessary but such a rule is not sufficient. If the effect being studied is rare, even a rule like t > 3 will produce a large number of false positives. I take a step back and explore the meaning of a p-value and detail its limitations. I offer a simple alternative approach known as the minimum Bayes factor which delivers a Bayesian p-value. I present a list of guidelines that are designed to provide a foundation for a robust, transparent research culture in financial economics. Finally, I offer some thoughts on the importance of risk taking (both from the perspective of both authors and editors) to advance our field.
About the Author: Wesley Gray, PhD
—
Important Disclosures
For informational and educational purposes only and should not be construed as specific investment, accounting, legal, or tax advice. Certain information is deemed to be reliable, but its accuracy and completeness cannot be guaranteed. Third party information may become outdated or otherwise superseded without notice. Neither the Securities and Exchange Commission (SEC) nor any other federal or state agency has approved, determined the accuracy, or confirmed the adequacy of this article.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of Alpha Architect, its affiliates or its employees. Our full disclosures are available here. Definitions of common statistics used in our analysis are available here (towards the bottom).
Join thousands of other readers and subscribe to our blog.