Recovering Missing Firm Characteristics with Attention-based Machine Learning
- Heiner Beckmeyer and Timo Wiedemann, University of Muenster (Germany)
- A version of this paper can be found here
- Want to read our summaries of academic finance papers? Check out our Academic Research Insight category.
What are the research questions?
Firm characteristics are often missing, which forces both researchers and practitioners to come up with workarounds when handling missing data. Previous approaches resorted to either dropping observations with missing entries or simply imputing the cross-sectional mean of a given characteristic. As both procedures accompany serious drawbacks (see below), there is a need for more advanced methods. The authors set up an attention-based machine learning model, motivated by recent advances in natural language to find answers to the following questions:
- How do firm characteristics relate to the cross-section of other – observed – characteristics and their historical evolution?
- How well does the proposed machine learning approach fare against competing approaches?
- How important is it to explicitly model nonlinear and interaction effects? How important is it to incorporate the temporal dynamics of the characteristics?
- On which information does the model rely when uncovering the latent structure governing firm characteristics?
What are the Academic Insights?
The authors show that:
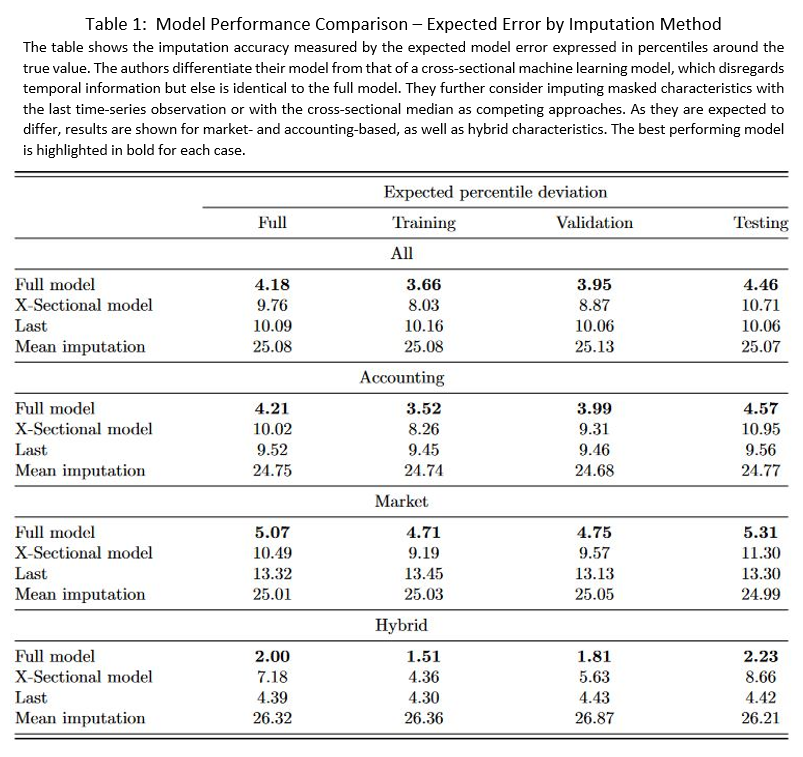
- The proposed model is highly accurate in extracting the latent structure underlying the evolution of observable firm characteristics. Their approach comfortably outperforms competing methods by a large scale. When using the model to reconstruct available firm characteristics in a controlled environment, the authors show an expected error of around 4 percentiles from the true value which is more than 2-times more accurate than the next-best method.
- Incorporating information about the temporal evolution of the characteristics is essential to boost the model’s ability to reconstruct characteristics. While some characteristics exhibit a high degree of autocorrelation, others predominantly depend on cross-characteristic information. Incorporating both types of information is therefore decisive. The authors highlight that the model is flexible enough to simultaneously uncover a wide range of processes governing the evolution of characteristics in a simulation study.
- Model sanity checks showing the distribution of the reconstructed (i.e., previously missing) characteristics attest internal validity, with results well in line with expectations. Information is more often missing for smaller firms, and those that would be considered of low quality.
- Revisiting the literature on risk factors in financial research shows that many risk premia are likely much smaller than previously thought. Adding to the recent debate on replicability in financial research, the authors highlight, in turn, that most risk premia remain significant. The completed dataset poses an additional out-of-sample hurdle for existing and new risk premia to pass.
- Recovered percentiles of firm characteristics have been made publicly available for future research here.
Why Does it Matter?
There is a tendency to simply drop observations with missing data points from the sample and base analyses on the reduced sample. Alternatively, missing characteristics are often imputed by the cross-sectional average. Both procedures, however, may seriously bias statistical inference if firm characteristics are not missing at random. For financial applications, as just one example, it is straightforward to see that this missing-at-random assumption likely does not hold empirically: smaller firms are generally required to provide less complete information. It is therefore of major importance to complete existing data sets of firm characteristics by accurately predicting missing entries in an informed fashion. Consequently, the method proposed in this paper may not only change the statistical significance of previous findings but can also be used to understand how far these findings carry over to a completed dataset, which ultimately leads to more-informed investment decisions.
The Most Important Chart from the Paper
The most important table of the paper shows the superior performance of the author’s model to competing approaches. At the same time, it highlights that the model can accommodate characteristics of various sources, showing consistently high performance for accounting- and market-based characteristics, as well as hybrid characteristics, which draw information from both sources. Table 1 is shown below. Note the generally poor performance of the commonly used mean imputation method.
Abstract
Firm characteristics are often missing. We set up an attention-based machine learning model borrowing ideas from state-of-the-art research in natural language processing to understand how characteristics relate to the cross-section of other – observed – firm characteristics and their historical evolution. Our model reconstructs firm characteristics with high accuracy and comfortably outperforms competing approaches. Revisiting the vast literature on risk factors in financial research reveals that disregarding the influence of missing observations likely overestimates the magnitude of factor premia. We also provide the filled distribution and raw values for all characteristics for future research.
About the Author: Heiner Beckmeyer
—
Important Disclosures
For informational and educational purposes only and should not be construed as specific investment, accounting, legal, or tax advice. Certain information is deemed to be reliable, but its accuracy and completeness cannot be guaranteed. Third party information may become outdated or otherwise superseded without notice. Neither the Securities and Exchange Commission (SEC) nor any other federal or state agency has approved, determined the accuracy, or confirmed the adequacy of this article.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of Alpha Architect, its affiliates or its employees. Our full disclosures are available here. Definitions of common statistics used in our analysis are available here (towards the bottom).
Join thousands of other readers and subscribe to our blog.