A Backtesting Protocol in the Era of Machine Learning
- Rob Arnott, Campbell Harvey, and Harry Markowitz
- Working paper
- A version of this paper can be found here
- Want to read our summaries of academic finance papers? Check out our Academic Research Insight category.
What are the Research Questions?
Data mining in finance has long been a concern for academic researchers. Campbell Harvey, one of the authors on this paper, is leading the effort to ensure the integrity of empirical finance research. For example, see here for a post on his address to the AFA.
The concerns associated with data mining aren’t going away. A monster increase in affordable computing power is facilitating the use of machine learning to create predictive algorithms in finance. Machine learning algorithms have built-in defenses against data mining, but they aren’t full proof. Moreover, the data required to do proper cross-validation does not exist in finance (at least in the investing realm…HFT may be a different story).(1)
This paper addresses a basic question related to the use of quantitative methods (to include machine learning) in the context of finance:
- Can we develop a sensible research protocol to deal with data-mining concerns?
What are the Academic Insights?
The authors outline a great research protocol. Below we outline the 7 steps of the protocol with our simple key takeaway on each. Readers should dig into the paper for more detail on each component to fully appreciate what is being proposed.
- Research motivation
- Start any research project with an ex-ante hypothesis, driven by economic foundations
- For a “winning strategy,” ask the following question: Who is on the other side of the trade?…and why?
- Multiple testing and statistical methods
- How many variables were tried?
- How many combinations were used?
- Do you have enough data to justify the value of additional complexity? Probably not.
- Data and sample choice
- Live with the data you’ve been dealt — don’t cherry pick, transform, “clean”, and
windsorize at random… - …but also make sure the data is accurate (e.g., market cap doesn’t exceed 10 trillion for 20 percent of the data set)
- Live with the data you’ve been dealt — don’t cherry pick, transform, “clean”, and
- Cross-validation
- There is no real “out of sample” at this point, save live trading data and fresh historical data.
- Model dynamics
- Beware of structural change. Humans are tricky animals with evolving tastes.
- Avoid “tweaking” a model based on live results.
- Complexity
- Keeps things as simple as possible, but no simpler.
- We don’t have enough data to truly assess the value of complexity.
- Research culture
- Reward good processes, not good results. (h.t. to Annie Duke for expressing a similar idea in “Thinking in Bets.”).
- Do you know where the bodies are buried? Probably not –Do your own research!
Why does it matter?
The authors make a simple, but important point:
When data are limited, economic foundations become more important.
Here is a framework for understanding how markets work.
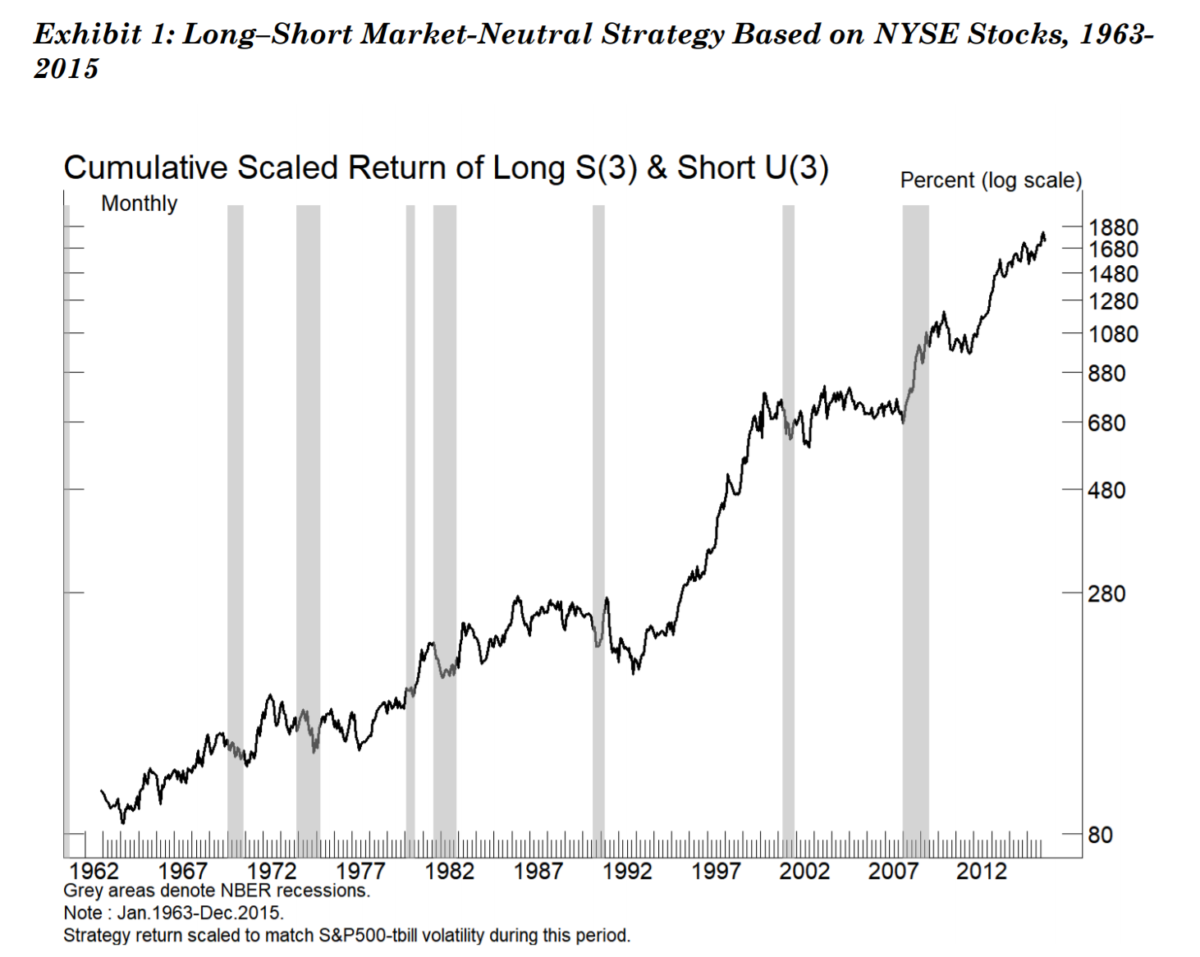
The Most Important Chart from the Paper
Here is a “magical” backtest of a strategy that is long all stocks with tickers with an “s” as the third letter and short stocks with tickers that have “u” as the third letter.
- In-sample and out-of-sample validation
- No correlation with known factors
- Low turnover
Abstract
Machine learning offers a set of powerful tools that holds considerable promise for investment management. As with most quantitative applications in finance, the danger of misapplying these techniques can lead to disappointment. One crucial limitation involves data availability. Many of machine learning’s early successes originated in the physical and biological sciences, in which truly vast amounts of data are available. Machine learning applications often require far more data than are available in finance, which is of particular concern in longer-horizon investing. Hence, choosing the right applications before applying the tools is important. In addition, capital markets reflect the actions of people, which may be influenced by others’ actions and by the findings of past research. In many ways, the challenges that affect machine learning are merely a continuation of the long-standing issues researchers have always faced in quantitative finance. While investors need to be cautious—indeed, more cautious than in past applications of quantitative methods—these new tools offer many potential applications in finance. In this article, the authors develop a research protocol that pertains both to the application of machine learning techniques and to quantitative finance in general.
About the Author: Wesley Gray, PhD
—
Important Disclosures
For informational and educational purposes only and should not be construed as specific investment, accounting, legal, or tax advice. Certain information is deemed to be reliable, but its accuracy and completeness cannot be guaranteed. Third party information may become outdated or otherwise superseded without notice. Neither the Securities and Exchange Commission (SEC) nor any other federal or state agency has approved, determined the accuracy, or confirmed the adequacy of this article.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of Alpha Architect, its affiliates or its employees. Our full disclosures are available here. Definitions of common statistics used in our analysis are available here (towards the bottom).
Join thousands of other readers and subscribe to our blog.