In recent years the field of empirical finance has faced challenges from papers arguing that there is a replication crisis because the majority of studies cannot be replicated and/or their findings are the result of multiple testing of too many factors. For example, Paul Calluzzo, Fabio Moneta, and Selim Topaloglu, authors of the 2015 study “When Anomalies Are Publicized Broadly, Do Institutions Trade Accordingly?” and David McLean and Jeffrey Pontiff, authors of the 2016 study “Does Academic Research Destroy Stock Return Predictability?” found that post-publication premiums decayed about one-third on average as institutional investors (particularly hedge funds) traded to exploit the anomalies.
The finding that factor premium returns could not be replicated should not be interpreted to mean there is a crisis in empirical finance. In fact, they should be entirely expected because institutional trading and anomaly publication are integral to the arbitrage process, which helps bring prices to a more efficient level. Such findings simply demonstrate the important role that both academic research and hedge funds (by way of their role as arbitrageurs) play in making markets more efficient. In other words, lower post-publication premiums do not mean there is a crisis; instead, it shows markets are working efficiently, as expected.
Even risk-based premiums that meet the criteria Andrew Berkin and I established in “Your Complete Guide to Factor-Based Investing”—the premium should be persistent, pervasive, robust, investable, and have logical explanations for why it should be expected to persist—can shrink due to increased cash flows. One would still assume that the premiums should not disappear in their entirety. On the other hand, if anomalies are the result of behavioral errors—or even investor preferences—and publication draws the attention of sophisticated investors, it is possible that post-publication, arbitrage would cause the premiums to disappear. Investors seeking to capture the identified premiums could quickly move prices in a manner that reduces the return spread between assets with high and low factor exposure. However, limits to arbitrage (such as aversion to shorting and its high cost, e.g., GameStop) can prevent arbitrageurs from correcting pricing mistakes. And the research, including the McLean and Pontiff study, shows that this tends to be the case when mispricing exists in less-liquid stocks, where trading costs are high.
Other criticisms have been made related to the zoo of factors, with literally hundreds reported to have been uncovered in the literature, many of which could have been the result of data mining exercises. With that said, the vast majority of those factors can be combined into a small number of composite factors. For example, the value factor consists of variables that measure price relative to such fundamentals metrics as book value, earnings, cash flow, and sales. And these ratios can even be adjusted for distress risk. The quality factor is a combination of fundamentals such as profitability, earnings quality, financial and operating leverage, and the degree of idiosyncratic risk. And there are many variations on momentum, including price momentum, analyst revisions, and fundamental momentum. For those interested, the research team at Robeco provided their view on navigating the factor zoo.
Theis Jensen, Bryan Kelly, and Lasse Pedersen make a major contribution to the factor literature with their March 2021 paper, “Is There a Replication Crisis in Finance?” They examined the validity of claims that findings had either:
“1. No internal validity. Most studies cannot be replicated with the same data (e.g., because of coding errors or faulty statistics) or are not robust in the sense that the main results cannot be replicated using slightly different methodologies and/or slightly different data. 2. No external validity. Most studies may be robustly replicated but are spurious and driven by ‘p-hacking,’ that is, finding significant results by testing multiple hypotheses without controlling the false discovery rate. Such spurious results are not expected to replicate in other samples or time periods, in part because the sheer number of factors is simply too large, and too fast growing, to be believable.”
They analyzed replicability of the main finance factors using a Bayesian model (Bayesian modeling is effective for making reliable inferences in the face of multiple testing) and a global data set of 153 factors across 93 countries. For each characteristic, they built the one-month holding period factor return within each country as follows: First, in each country and month, they sorted stocks into characteristic terciles (top/middle/bottom third) with breakpoints based on non-microstocks in that country. For each tercile, they computed its “capped value weight” return, meaning they weighted stocks by their market equity winsorized at the NYSE 80th percentile. This construction ensured that tiny stocks had tiny weights and any one mega-stock did not dominate a portfolio, seeking to create tradable, yet balanced, portfolios. The factor was then defined as the high-tercile return minus the low-tercile return, corresponding to the excess return of a long-short zero-net-investment strategy.
They also proposed:
“a factor taxonomy that algorithmically classifies factors into 13 themes possessing a high degree of within-theme return correlation and economic concept similarity, and low across-theme correlation.”
The 13 themes were Accruals∗, Debt Issuance∗, Investment∗, Leverage∗, Low Risk, Momentum, Profit Growth, Profitability, Quality, Seasonality, Size∗, Skewness∗ , and Value, where the star (∗) indicates that these factors bet against the corresponding characteristic (e.g., accrual factors go long stocks with low accruals while shorting those with high accruals). Return data was from CRSP for the U.S. (beginning in 1926) and from Compustat for all other countries (beginning in 1986 for most developed countries). Following is a summary of their findings:
- The majority of factors do replicate, do survive joint modeling of all factors, do hold up out-of-sample, are strengthened (not weakened) by the large number of observed factors, are further strengthened by global evidence, and the number of factors can be understood as multiple versions of a smaller number of themes.
- While a nontrivial minority of factors failed to replicate in their data, the overall evidence is much less disastrous than some people suggest.
- Using their Bayesian approach, the CAPM replication rate (the percentage of factors with a statistically significant average excess return) was 85 percent. This was true for both the U.S. and global data (providing out-of-sample tests).
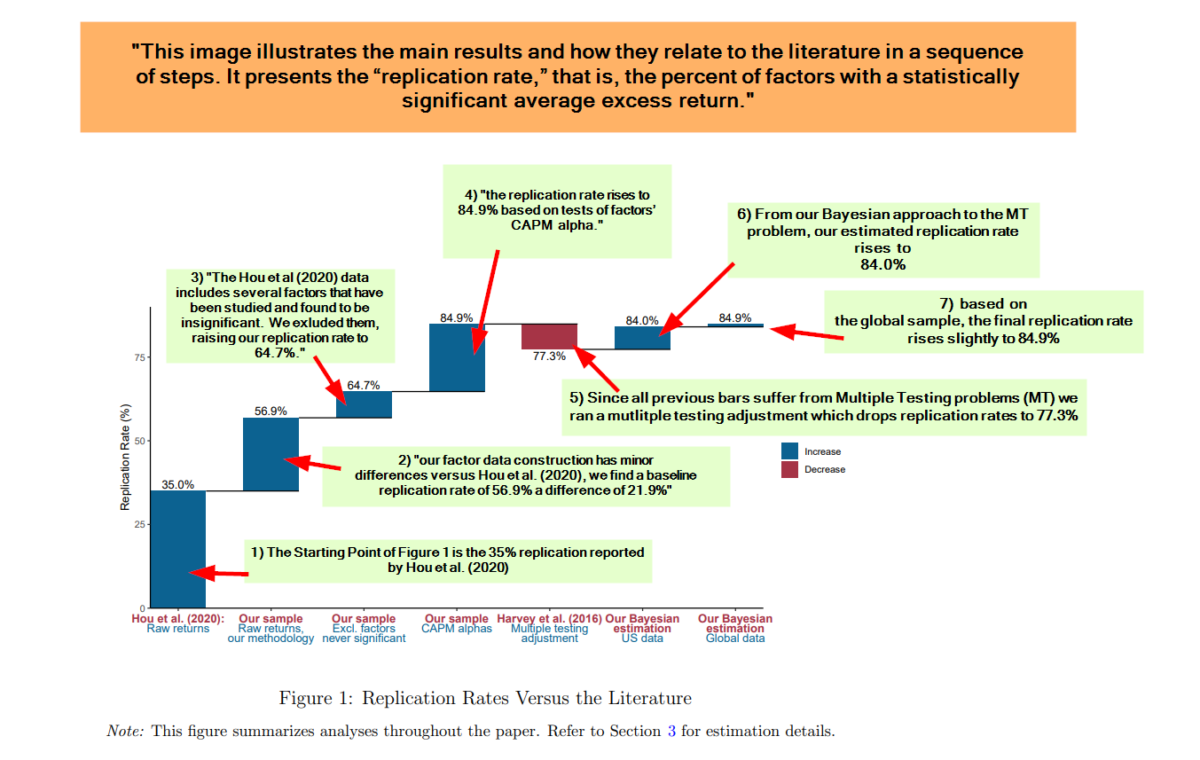
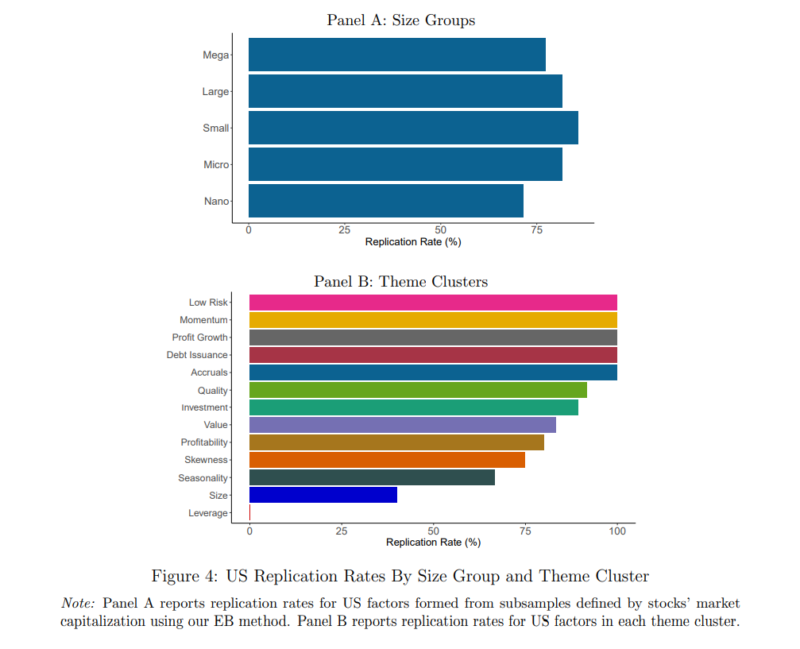
- There was a replication rate of greater than 75 percent in 10 of the 13 themes (based on the Bayesian model, including an adjustment for multiple testing), with the exceptions of the Seasonality, Leverage, and Size factor themes.
- Factors demonstrated a high replication rate throughout the size distribution—criticisms of factor replicability based on arguments around stock size or liquidity are largely groundless.
- Ten of the 13 themes entered into the tangency (efficient) portfolio with significantly positive weights. The three displaced themes were Profitability, Investment, and Size.
- Many factors were highly correlated, well in excess of 50 percent on average within themes, and many themes contributed significantly to the tangency portfolio—many different factors bear distinct information about the economy-wide risk-return tradeoff. In other words, most themes have alpha with respect to all others.
- Value factors became stronger when controlling for other effects because of their hedging benefits relative to momentum, quality, and leverage. And the Leverage cluster became one of the most heavily weighted, in large part due to its ability to hedge value and low-risk factors.
Their findings led Jensen, Kelly and Pedersen to conclude:
“US equity factors have a high degree of internal validity in the sense that over 80% of factors remain significant after modifications in factor construction that make all factors consistent, more implementable, while still capturing the original signal and after accounting for multiple testing concerns.”
Importantly, their U.S. evidence is consistent with the global data. They added:
“We show that some out-of-sample factor decay is to be expected in light of Bayesian posteriors based on published evidence. Therefore, the new evidence from post-publication data largely confirms the Bayesian’s beliefs, which has led to relatively stable Bayesian alpha estimates over time.”
Takeaways
For investors, the important takeaway is that despite the proliferation in the literature of a zoo of hundreds of factors, there are only a small number needed to explain the vast majority of differences in returns of diversified portfolios. And those factors hold up to replication tests. In “Your Complete Guide to Factor-Based Investing,” Andrew Berkin and I suggest that investors could limit their tour of that factor zoo to just the following equity factors: market beta, size, value, profitability/quality, and momentum. We also suggest that investors could consider including the low volatility/low beta factor as well. With that said, in an appendix we added this important insight:
“Once you have gained exposure to the factors we recommend, there is not a great deal of potential to add much, if any, benefit through exposure to additional factors.”
We also explain that it is more efficient to target the factors you want exposure to through a multi-style fund rather than through single-style funds.
About the Author: Larry Swedroe
—
Important Disclosures
For informational and educational purposes only and should not be construed as specific investment, accounting, legal, or tax advice. Certain information is deemed to be reliable, but its accuracy and completeness cannot be guaranteed. Third party information may become outdated or otherwise superseded without notice. Neither the Securities and Exchange Commission (SEC) nor any other federal or state agency has approved, determined the accuracy, or confirmed the adequacy of this article.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of Alpha Architect, its affiliates or its employees. Our full disclosures are available here. Definitions of common statistics used in our analysis are available here (towards the bottom).
Join thousands of other readers and subscribe to our blog.