Non-Standard Errors
- 164 authors
- Working paper
- A version of this paper can be found here
- Want to read our summaries of academic finance papers? Check out our Academic Research Insight category
What are the research questions?
Most readers are familiar with p-hacking and the so-called replication crisis in financial research (see here, here, and here for differing views). Some claim that these research challenges are driven by a desire to find ‘positive’ results in the data because these results get published, whereas negative results do not get published (the evidence backs these claims).
But this research project identifies and quantifies another potential issue with research — the researchers themselves! This “noise” created by differences in empirical techniques, programming language, data pre-processing, and so forth are deemed “non-standard-errors,” which may contribute even more uncertainty in our quest to determine intellectual truth. Yikes!
In this epic study, the #fincap community delivers a fresh standardized dataset and a set of hypotheses to 164 research teams across the globe. The authors then try and identify the variation in the results due to differences in the researcher’s approach to tackling the problem.
The research questions the paper seeks to address are as follows:
- How large are non-standard errors for financial research?
- What explains the differences?
- Does peer-review minimize these differences?
- How aware are researchers of the differences?
What are the Academic Insights?
- How large are non-standard errors for financial research?
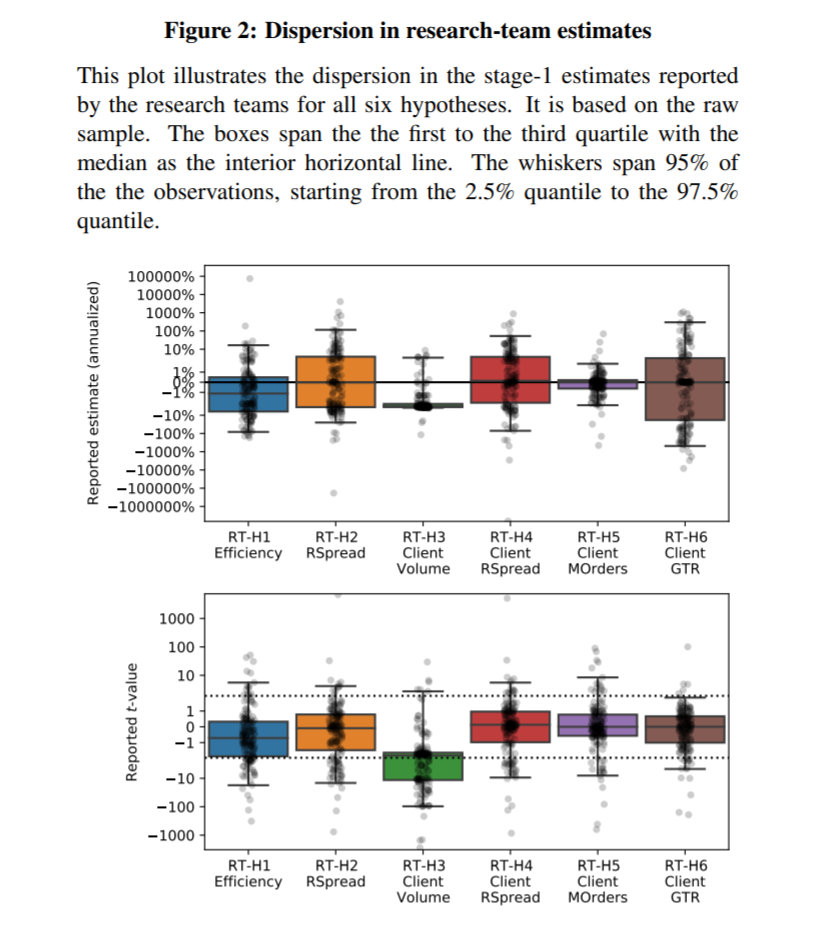
- Very large. On basic questions such as “How has market efficiency changed over time?” one gets a huge dispersion in ‘evidence-based’ insights.
- What explains the differences?
- Hard to say, but intuitive concepts such as team quality, process quality, and paper quality are examined. The evidence, collectively, seems to suggest it is hard to explain the research differences on the dimensions listed.
- Does peer-review minimize these differences?
- Yes. Which reinforces why it is important to run a peer-review process and have people review your work with a critical eye.
- How aware are researchers of the differences?
- Not aware at all. But this is not surprising — we already know humans are generally confused, on average.
Why does it matter?
We already knew that data-mining was a problem in academic research and researchers are working hard to fix this problem. However, this paper brings up a new source of variability — the researchers themselves! And the sad part is all of these variations and biases embedded in research may not be tied to nefarious motives — they are simply part of the landscape and should be considered when reviewing academic research.
Of course, we should be clear that the takeaway is NOT to disregard academic research and the scientific approach to learning new things. Relying on intuition and gut feel is a process that will likely lead to even more bias and warped conclusions! So while academic research is not flawless, its the best we got. To me, the key data point from this paper is that we should reinforce peer-review processes and establish a research culture where criticism is applauded, not derided.
The most important chart from the paper
Abstract
In statistics, samples are drawn from a population in a data-generating process (DGP). Standard errors measure the uncertainty in sample estimates of population parameters. In science, evidence is generated to test hypotheses in an evidence-generating process (EGP). We claim that EGP variation across researchers adds uncertainty: non-standard errors. To study them, we let 164 teams test six hypotheses on the same sample. We find that non-standard errors are sizeable, on par with standard errors. Their size (i) co-varies only weakly with team merits, reproducibility, or peer rating, (ii) declines significantly after peer-feedback, and (iii) is underestimated by participants.
About the Author: Wesley Gray, PhD
—
Important Disclosures
For informational and educational purposes only and should not be construed as specific investment, accounting, legal, or tax advice. Certain information is deemed to be reliable, but its accuracy and completeness cannot be guaranteed. Third party information may become outdated or otherwise superseded without notice. Neither the Securities and Exchange Commission (SEC) nor any other federal or state agency has approved, determined the accuracy, or confirmed the adequacy of this article.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of Alpha Architect, its affiliates or its employees. Our full disclosures are available here. Definitions of common statistics used in our analysis are available here (towards the bottom).
Join thousands of other readers and subscribe to our blog.