Machine learning models have proven effective in predicting stock returns using lagged stock characteristics, but their success is influenced by a wide range of modeling choices. One critical, yet often overlooked, choice is how stocks are weighted in the objective function during training, with equally weighted (EW) approaches being the norm. This paper investigates how such choices impact cross-sectional return predictability and the performance of trading strategies derived from these predictions, focusing on the interplay between objective function design and model outcomes.
Choices Matter When Training Machine Learning
Models For Return Prediction
- Clint Howard
- Financial Analyst Journal, 2024
- A version of this paper can be found here
- Want to read our summaries of academic finance papers? Check out our Academic Research Insight category
What are the Research Questions?
The main research questions addressed in this paper can be summarized as follows:
- How do modeling choices, such as the weighting of stocks in the objective function, impact the predictive performance of machine learning models and their derived trading strategies?
- How does re-weighting observations by market capitalization groups affect cross-sectional return predictability and the performance of trading strategies?
- What is the role of data heterogeneity in influencing the predictive performance of machine learning models for stock returns, particularly across market capitalization groups?
- Can training group-specific machine learning models mitigate biases caused by overrepresentation of smaller stocks in the training data?
What are the Academic Insights?
By running run a horse race of the various frameworks and proxies used to generate long-term E(R) forecasts, the authors find:
- Modeling choices significantly impact the predictive performance of machine learning models by influencing how well the models capture cross-sectional heterogeneity in stock returns. Weighting schemes like equally weighted (EW) or market-capitalization weighted (VW) can introduce biases, affecting predictions and trading strategy performance. For instance, overrepresentation of smaller stocks in EW approaches often reduces generalizability to larger stocks, while group-specific models or alternative weighting can improve both prediction accuracy and trading outcomes.
- Re-weighting observations by market capitalization groups enhances cross-sectional return predictability and trading strategy performance by addressing data heterogeneity. It allows models to better capture differences in return patterns across market-cap groups, improving predictions for both small and large stocks. This approach mitigates biases from overrepresentation of smaller stocks in the training data and results in more robust and effective trading strategies.
- Data heterogeneity significantly affects the predictive performance of machine learning models by creating disparities in return patterns across market capitalization groups. Smaller stocks, with higher volatility and unique characteristics, dominate training data in equally weighted models, leading to biases and reduced generalization to larger stocks. Addressing this heterogeneity improves model accuracy and ensures better performance across diverse stock groups.
- YES, training group-specific machine learning models can mitigate biases caused by the overrepresentation of smaller stocks. By focusing on distinct market capitalization groups, these models better capture group-specific return patterns, reducing the dominance of smaller stocks and improving predictive performance and transferability across different stock categories.
Why does this study matter?
This study matters because it highlights how seemingly minor modeling choices, such as the weighting of stocks or group-specific training, significantly impact the predictive performance and economic utility of machine learning models in finance. By addressing data heterogeneity and biases, the findings provide actionable insights for improving stock return predictions and trading strategies, offering value to both academics and practitioners. It underscores the importance of thoughtful model design in achieving reliable and interpretable financial predictions.
The Most Important Chart from the Paper:
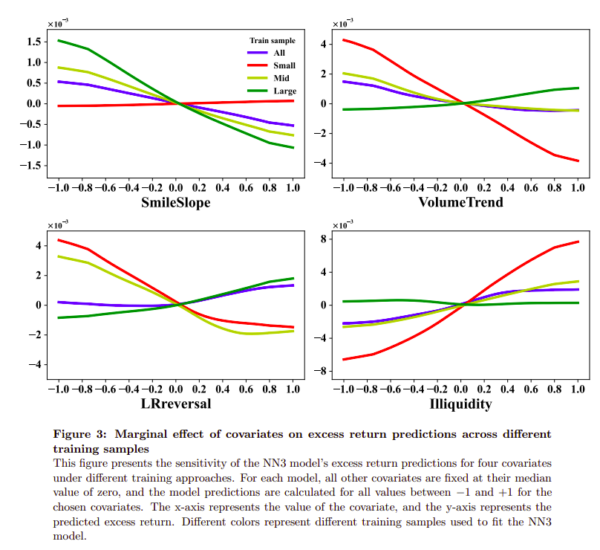
The results are hypothetical results and are NOT an indicator of future results and do NOT represent returns that any investor actually attained. Indexes are unmanaged and do not reflect management or trading fees, and one cannot invest directly in an index.
Abstract
Applying machine learning to cross-sectional stock return prediction requires careful consideration of modeling choices. Common approaches that fail to account for heterogeneity or imbalanced stock representation in training data can lead to suboptimal performance. I study two strategies to address these issues: training group–specific models and predicting relative returns. Both approaches yield similar economic improvements over models trained on the full cross-section of U.S. stock returns, with value-weighted trading strategies benefiting significantly. The findings underscore the importance of aligning machine learning modeling decisions with desired economic outcomes and provide guidance for researchers and practitioners seeking robust machine learning models.

About the Author: Elisabetta Basilico, PhD, CFA
—
Important Disclosures
For informational and educational purposes only and should not be construed as specific investment, accounting, legal, or tax advice. Certain information is deemed to be reliable, but its accuracy and completeness cannot be guaranteed. Third party information may become outdated or otherwise superseded without notice. Neither the Securities and Exchange Commission (SEC) nor any other federal or state agency has approved, determined the accuracy, or confirmed the adequacy of this article.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of Alpha Architect, its affiliates or its employees. Our full disclosures are available here. Definitions of common statistics used in our analysis are available here (towards the bottom).
Join thousands of other readers and subscribe to our blog.