Predictably Unequal: The Effects of Machine Learning on Credit Markets
- Fuster, Goldsmith, Ramadorai and Walther
- Journal of Finance, 2022
- A version of this paper can be found here
- Want to read our summaries of academic finance papers? Check out our Academic Research Insight category
What are the Research Questions?
Sophisticated statistical learning techniques such as machine learning are increasingly being utilized across sectors and businesses. Typically we attribute, or assume, machine learning will create better outcomes than simple human analysis but are there unintended consequences from using these new tools?
In this paper the authors ask the following question:
- Are there distributional consequences across societally important categories such as race, income, or gender of the use of machine learning techniques in household credit market analysis?
The primary idea behind this research is that a more sophisticated statistical technology (in the sense of reducing predictive mean squared error) produces predictions with greater variance than a more primitive technology. These technologies range from a simple logistic regression of default outcomes based on borrowers and default variables to random forest machine learning models. Said differently, improvements in predictive technology act as mean-preserving spreads for predicted outcomes—in this case, predicted default propensities on loans, which also means that there will always be some borrowers considered less risky by the new technology, or “winners”, while other borrowers will be deemed riskier “losers”, relative to their position under the pre-existing technology.
What are the Academic Insights?
The authors study a large administrative dataset of loans in the US mortgage market (data collected under the Home Mortgage Disclosure Act (HMDA) + the McDashTM mortgage servicing dataset which is owned and licensed by Black Knight with borrowers’ race, ethnicity, and gender, as well as mortgage characteristics and default outcomes.
The authors find:
- Machine learning technology delivers statistically significantly higher out-of-sample predictive accuracy for default than the simpler logistic models.
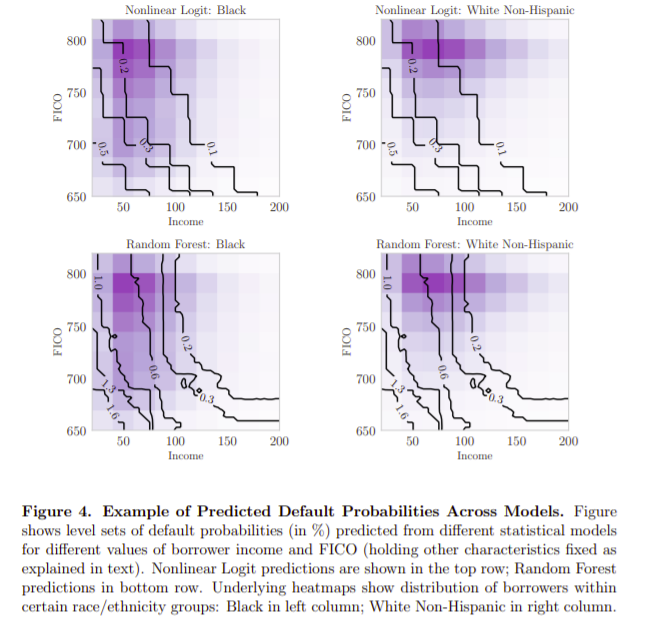
- Predicted default propensities across race and ethnic groups look very different under the more sophisticated technology than under the simple technology. For example, while a large fraction of borrowers belonging to the majority group (e.g., White non-Hispanic) experience lower estimated default propensities under the machine learning technology than the less sophisticated model, these benefits do not accrue to the same degree to some minority race and ethnic groups (e.g., Black and Hispanic borrowers).
- Black and Hispanic borrowers get very different rates from one another (within-group) under the machine learning technology.
Why does it matter?
Overall, the picture is mixed. On the one hand, the machine learning model is a more effective model, predicting default more accurately than the more primitive technologies. Additionally, it does appear to provide credit to a slightly larger fraction of mortgage borrowers and to slightly reduce cross-group dispersion in acceptance rates. However, the main effects of the improved technology are the rise in the dispersion of rates across race groups, as well as the significant rise in the dispersion of rates within race groups, especially for Black and Hispanic borrowers.
The Most Important Chart from the Paper:
Abstract
Innovations in statistical technology, including in predicting creditworthiness, have sparked concerns about distributional impacts across categories such as race. Theoretically, distributional consequences of better statistical technology can come from greater flexibility to uncover structural relationships, or from triangulation of otherwise excluded characteristics. Using data on US mortgages, we predict default using traditional and machine learning models. We find that Black and Hispanic borrowers are disproportionately less likely to gain from the introduction of machine learning. In a simple equilibrium credit market model, machine learning increases disparity in rates between and within groups; these changes are primarily attributable to greater flexibility.

About the Author: Elisabetta Basilico, PhD, CFA
—
Important Disclosures
For informational and educational purposes only and should not be construed as specific investment, accounting, legal, or tax advice. Certain information is deemed to be reliable, but its accuracy and completeness cannot be guaranteed. Third party information may become outdated or otherwise superseded without notice. Neither the Securities and Exchange Commission (SEC) nor any other federal or state agency has approved, determined the accuracy, or confirmed the adequacy of this article.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of Alpha Architect, its affiliates or its employees. Our full disclosures are available here. Definitions of common statistics used in our analysis are available here (towards the bottom).
Join thousands of other readers and subscribe to our blog.