Developments in the use of Large Language Models (LLM) have successfully demonstrated a set of applications across a number of “domains”, most of which deal with a very wide range of topics. While the experimentation has elicited lively participation from the public, the applications have been limited to broad capabilities and general-purpose skills. Only recently have we seen a focus on specific domains like FinTech. BloombergGPT is a large language model (LLM) developed specifically for financial tasks and trained on the arcane language and mysterious concepts of finance. In this article, the authors trained the LLM on a large body of financial textual data, evaluated it on several financial language processing tasks and found it performed at a significantly higher level than several other state-of-the-art general purpose LLMs.
BloombergGPT: A Large Language Model for Finance
- Shijie Wu1, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann
- Working Paper, arXivLabs-Cornell University
- A version of this paper can be found here
- Want to read our summaries of academic finance papers? Check out our Academic Research Insight category.
What are the research questions?
- What is a Large Language Model (LLM)?
- How did Bloomberg’s LLM perform relative to other open-sourced models?
- What were the sources of textual data?
What are the Academic Insights?
- Essentially, an LLM is a neural network designed for text, concepts, etc., from any discipline, trained to fulfill a specific task(s) on very large amounts of ‘text-type’ data using a computerized natural language model.
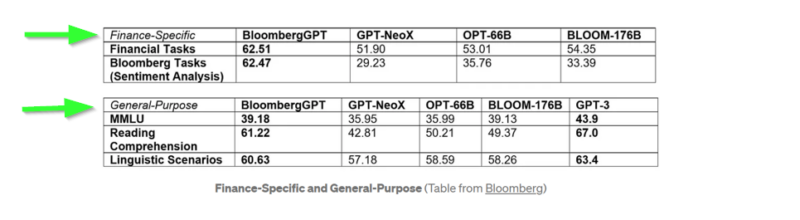
- The performance put up by Bloomberg’s LLM was evaluated for finance-specific and general-purpose tasks. BloombergGPT outperformed three open LLMs of comparable size on financial tasks while still performing on at least an equal basis for general natural language processing (NLP) tasks. The dataset of 363 billion tokens was constructed from comprehensive sources collected by Bloomberg itself and 345 billion tokens from general purpose data sources. The combined set was named FinPile which included financial documents collected by Bloomberg (in English) over 20 years or more. The Bloomberg archive included news, filings, press releases, web-scraped financial documents, and social media. Combined with the general-purpose texts, a well-rounded model was produced capable of handling a wide array of financial texts.
3. The datasets included FinPile and Public sources. The general-purpose (Public) set typically used by many LLMs was included at 49% of the total versus 51% from FinPile.

Why does it matter?
A comment from Gideon Mann, Head of Bloomberg’s ML Product and Research team:
“The quality of machine learning and NLP models comes down to the data you put into them. Thanks to the collection of financial documents Bloomberg has curated over four decades, we were able to carefully create a large and clean, domain-specific dataset to train a LLM that is best suited for financial use cases.”
The most important chart from the paper

Abstract
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg’s extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most
accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. As a next step, we plan to release training logs (Chronicles) detailing our experience in training BloombergGPT.
About the Author: Tommi Johnsen, PhD
—
Important Disclosures
For informational and educational purposes only and should not be construed as specific investment, accounting, legal, or tax advice. Certain information is deemed to be reliable, but its accuracy and completeness cannot be guaranteed. Third party information may become outdated or otherwise superseded without notice. Neither the Securities and Exchange Commission (SEC) nor any other federal or state agency has approved, determined the accuracy, or confirmed the adequacy of this article.
The views and opinions expressed herein are those of the author and do not necessarily reflect the views of Alpha Architect, its affiliates or its employees. Our full disclosures are available here. Definitions of common statistics used in our analysis are available here (towards the bottom).
Join thousands of other readers and subscribe to our blog.